Cogent Raises $42M Series A - Read more here
Nov 3, 2025
Cogent Community’s Agent vs. General LLMs: A Head-to-Head Comparison of Accuracy

Alexander Semien, Marketing

Meet Cogent Community
Cogent Community is a free solution for security practitioners. It pairs Cogent’s agentic AI with industry-leading intelligence from VulnCheck, the premier source for open vulnerability and exploit intelligence. Community delivers faster research, plain-language explanations, and next steps in seconds so defenders can keep pace with AI-enabled adversaries.
What’s inside
Discover Feed: A customizable, real-time feed for vulnerability and exploit intelligence showing breaking disclosures, trending activity, and the topics you follow.
AI-Powered Research Assistant: Ask in natural language. Community compares sources, cites evidence, and explains impact in plain terms.
Community Agent: Precise mitigation and remediation recommendations based on prompted asset, owner, and business context.
Executive Summary
Practitioners rely on Cogent Community when speed and accuracy matter. The right answer from our agent can be the difference between containment and a breach, which made our goal simple: build the most accurate domain-trained agents we can and prove they outperform strong general models on real tasks.
We used CTI-Bench, a comprehensive suite of benchmark tasks and datasets that evaluates large language models in Cyber Threat Intelligence. It focuses on two tasks: Root Cause Mapping, where the model reads a CVE description and selects the correct CWE class using the benchmark’s single canonical label as ground truth, and Multiple Choice Questions, where the model answers technical security questions drawn from authoritative sources. We ran Community’s CVE Agent head to head against leading lab models, with and without web search, using the same prompts and the same scoring to keep the comparison fair and focused on outcomes.
Highlights
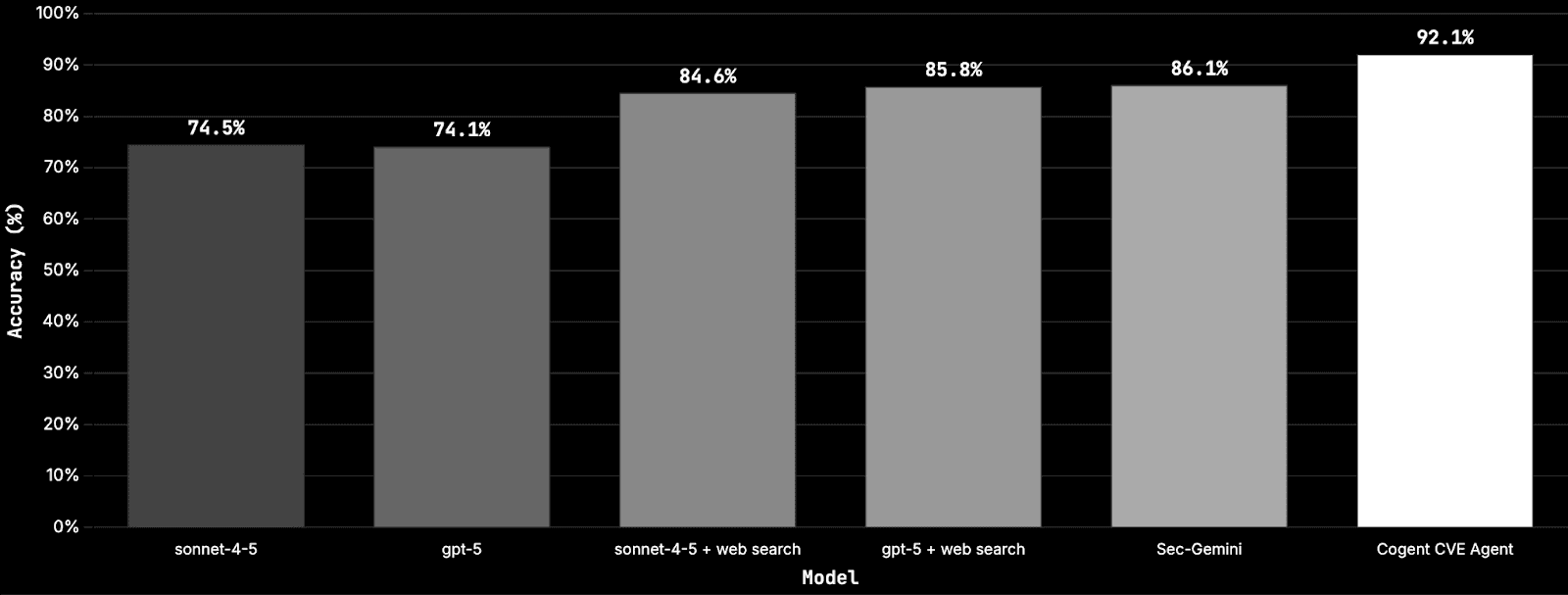
Root Cause Mapping: 92.1 percent accuracy, +6.0 points vs Sec-Gemini, +6.3 vs GPT-5 + Web Search.
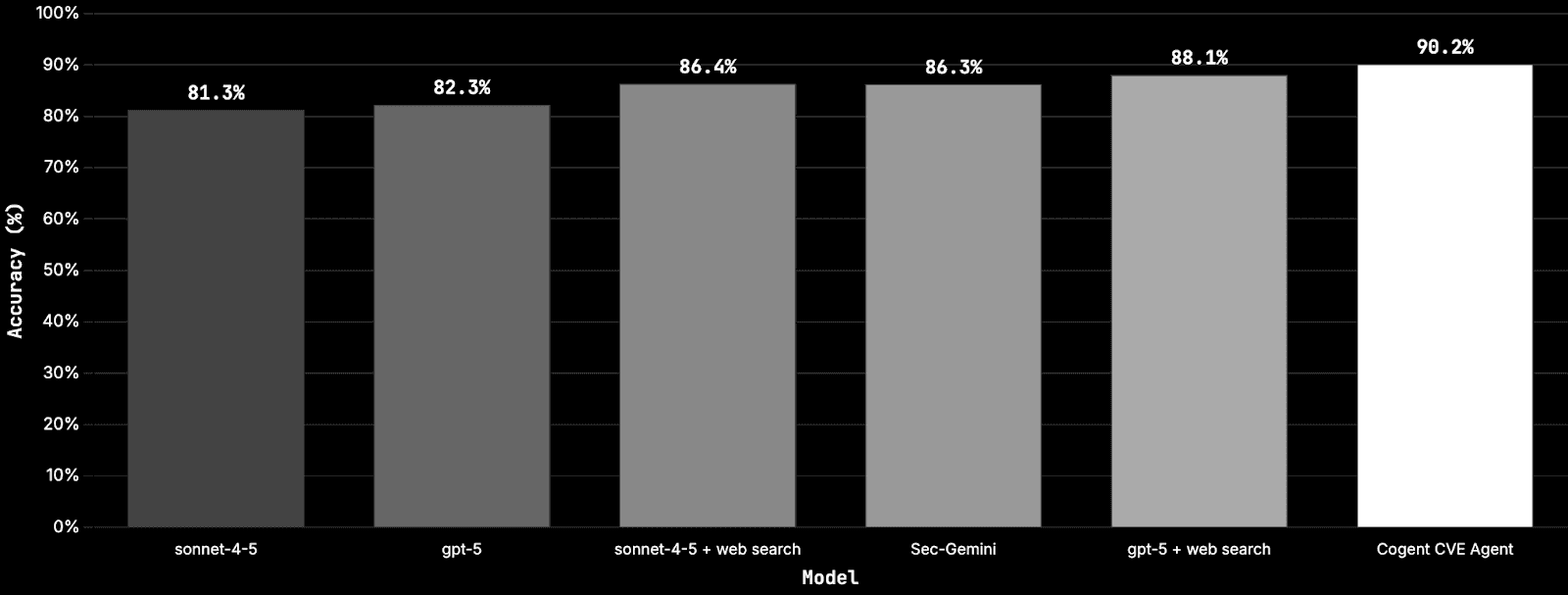
Multiple Choice Questions: 90.2 percent accuracy, +3.9 points vs Sec-Gemini, +2.1 vs GPT-5 + Web Search.
Why it matters: fewer misclassifications during intake, cleaner prioritization, faster mitigation plans, and clearer program reporting.
What This Means for Teams
Safer decisions, faster triage, and clearer plans at the volume where every percentage point compounds.
Why Our Agent Is Better
Community’s agent starts from verified intelligence in VulnCheck, normalizes products and versions, and applies CWE-aware reasoning to select the true root cause before recommending steps. General models often anchor on keywords or conflicting pages, which leads to wrong labels and generic guidance.
Comparison Research Design: CTI-Bench
CTI-Bench is a comprehensive suite of benchmark tasks and datasets designed to evaluate large language models in Cyber Threat Intelligence. It focuses on two tasks: Root Cause Mapping (RCM) and Multiple Choice Questions (MCQ). In RCM, a model reads a CVE description and selects the correct CWE class. CWE is the Common Weakness Enumeration, a standardized catalog of root-cause weakness types used by NVD, vendors, and security teams. CTI-Bench provides one canonical CWE label per CVE in its answer key, which serves as the ground truth for scoring. RCM and MCQ are both graded by exact match, and accuracy is reported as a percentage.
How We Compared
All systems saw identical prompts and were scored the same way. Baselines were strong general-purpose chat models, tested with and without web search. Only the Community CVE Agent read VulnCheck. “pp” refers to percentage points. Community’s CVE Agent runs on Anthropic Sonnet 4-5 and layers Cogent’s domain logic on top: VulnCheck grounding, CWE-aware decision rules, and workflow outputs. The gains shown here reflect the full system, not the base model alone.
Results
Root Cause Mapping (RCM)
Given a CVE description, can the model select the correct CWE category. CTI-Bench supplies a single canonical CWE label as the ground truth for each CVE.
Why It Matters
Prioritization and deduping improve when the root cause is labeled correctly.
Remediation and validation steps differ by weakness type.
Trend tracking becomes consistent across products, services, and teams.
Program and board reporting rolls up cleanly to parent classes.
Scores
Lift and Practical Impact
+6.0 points vs Sec-Gemini and +6.3 vs GPT-5 + Web Search.
At 1,000 CVEs, that is roughly 60 and 63 fewer misclassifications, which reduces rework in intake and keeps change windows aimed at the right fixes.
Multiple Choice Questions (MCQ)
Answer technical questions about CVEs, MITRE ATT&CK, and security concepts drawn from authoritative sources. Scoring is exact match on the correct choice.
Why It Matters
Investigations move faster with fewer plausible-but-wrong answers.
Analysts make better judgments under pressure.
Teams reinforce correct reasoning patterns across domains.
Scores
Lift and Practical Impact
+3.9 points vs Sec-Gemini and +2.1 vs GPT-5 + Web Search.
Per 1,000 questions, that is about 39 and 21 fewer wrong answers. At 2,500 questions, the reductions are about 98 and 53, which shortens investigations and reduces churn.
Selected RCM Examples
These examples come from the RCM task, where each system reads a CVE description and must select the correct CWE. Prompts were identical and scoring was exact match on the benchmark’s ground truth label. We chose three cases where the Cogent CVE Agent was correct and GPT-5 + Web Search was not, to show common failure modes we see in intake.
CVE | Prompt signal (short) | Ground truth CWE | Agent | GPT-5 + Web Search | Why it matters |
2022-48620 | “buffer overflow in epoll_wait if maxevents is large” | CWE-120 Classic Buffer Overflow | CWE-120 | CWE-787 Out-of-bounds Write | CWE-120 points to classic overflow checks and tests. CWE-787 is broader and can lead to generic fixes. |
2024-23049 | “RCE via log4j component” | CWE-77 Command Injection | CWE-77 | CWE-502 Deserialization of Untrusted Data | Not every log4j-related RCE is deserialization. Correct class changes mitigations and verification steps. |
2024-22771 | “attack when default admin ID/PW is used” | CWE-798 Hard-coded Credentials | CWE-798 | CWE-1392 Use of Default Credentials | Defaults are a symptom. Hard-coded secrets are the cause and require different remediation and validation. |
Why Our Agent Is Superior
Community’s CVE Agent is built for one job: produce accurate responses to security questions and effective remediation guidance. The edge in RCM and MCQ comes from how the system is designed, not just which model is underneath.
1) Specialized Domain Knowledge
Understands CWE taxonomy and hierarchy, choosing the right parent or child class.
Recognizes vulnerability and exploit patterns across products and versions.
Interprets security terminology correctly, including LFR, RCE, and privilege escalation.
2) Structured Analysis
Parses CVE descriptions for technical indicators like functions, vectors, and impact.
Identifies patterns and maps to CWE with decision rules for consistent labels.
Distinguishes root cause from symptom, avoiding false precision.
3) Authoritative Sources
Reads VulnCheck for normalized records, aliases, and exploit evidence.
Uses NVD and CWE definitions for context and classification criteria.
Checks reputable exploit repositories and research to resolve conflicts.
4) Built for Real Workflows
Fast, consistent classification for high-volume triage.
Actionable guidance aligned to assets, owners, and change windows.
Integration-ready outputs that roll up cleanly to program reporting.
Where This Helps Most
Vulnerability Management | Security | Application |
|
|
|
Limitations and What to Watch
When public signals are sparse or contradictory, both the agent and general models can struggle. The agent calls out uncertainty and what evidence would increase confidence.
MCQ gains are smaller than RCM gains. That is expected because MCQ rewards broad recall, while RCM rewards precise mapping.
Results vary with data slices and configurations. Teams should validate on their own distributions and tasks.
Get Cogent Community
Community is available at no cost for security practitioners.
Sign up: https://www.cogent.security/community
Reference: CTI-Bench: A Benchmark for Evaluating LLMs in Cyber Threat Intelligence (arXiv: 2406.07599).
Special thanks to Anirudh Ravula, Geng Sng, and Mariam McLellan from Cogent for experiment design and research support.
